I just wanted to thank you for all of your hard work. You saved us a lot of time during installation. And the user interface is nothing short of excellent; it is extremely easy to use.
If you got the "HD" checkmark set, it will use img2img to add more details. That works well for landscapes/cities, but for people it might add unwanted faces.
In that case you'd want to remove the "HD" checkmark, so the image only gets sharper. :)
You can increase the maximum step count by... 1) Options -> open settings folder 2) Close aiimages. 3) Open settings.json with Editor. Edit the line ""iMaxStepCount": 150,". Save it. 4) Open aiiamges.
Sorry that there's not easier way yet. :( Will come in the future. <3
Thank you for your reply. Can I also ask if there is a way to choose a custom output folder different from the default one? I wanted to use the software in an M2 and output it on a external HD
I've been using this thing non-stop like 5+ hours a day. It just is so much fun.
I've spent the past day or so reading up on the embeddings/textual inversion and google colab/Dreambooth options as well to train the stable diffusion model more, but it seems every option becomes difficult to various reasons - and the other options require you to pay to run a server farm to train the model for you.
Is there any chance you are working on or can put together a UI so we can train and create our own model.ckpt file directly in the software? I've looked at other options but require installing Ubuntu in Windows, or having to go through all that difficult Python scripts when we just want to be able to drag and drop images, click go and come back to a sweet new file.
Please, if you could just include a simple UI it would mean the world to myself and so many others. Your option to generate unlimited images makes it far better than the other stable diffusion UIs.
I think you cannot train an own model.ckpt on consumer hardware. :( And it needs about 40k images with labels. But there are two things I might add.
A) Embeddings. You can find those in the documentation for invokeai. Basically: Give the ai "5 images + 1 tag + 1h training on a RTX 3090ti = ai learned new word". I could create a UI for that already.
B) Dreambooth. I don't understand it yet, but it's kinda "embeddings but better", if I understood it correctly. It is not implemented in the backend yet, but it will be implemented. I'm kinda hyped for that, because it allows to create the same person in different poses. <3
Pretty impressed by what it can spit down with a nice prompt and some fine tuning. It can even manage some pretty face and hands instead of the distorted monstruosity that i saw in some other browser based generator.
It seem to get stuck on an infinite loading while i try to upscale or repeat an already upscaled / repeated image, but still for a generous price tag of free is one of the best tool that i've ever seen
Thank you. All other functions work normally. Only in the inpaint, if you want to modify the image partially, it will be stuck all the time. Why? (3060ti)
recently ive seen some rlly cool ai animation videos that show a bunch of ai generated images together like an animated video using stable diffusion and I was just curious if its possible to do with this?
would greatly appreciate some kind of integration or pipeline for Textual Inversion to use our own images to train for those of us that are far less program savvy!
With the newest version, aiimages already sets the right values to run on the GPU. (It only won't work on the 1650, because it doesn't have enough VRAM for the fix. :( )
Not with my experience. I rather accidently created some nsfw stuff just by adding the word "sexy" or so. Try adding more words describing what you want?
e.g;I selected an input image, then deleted that input image from the program's folder.(using windows explorer)
then all the pictures I wanted to reprocess took hundreds of seconds, the program went into an infinite loop and the rendering was never finished. gpu usage is %1, cpu usage is %1. vram and ram is totally empty.
You need to fix the coding. There are dozens of ways to put the program in an infinite loop. CPU and gpu usage stays at 1% during this process. this has nothing to do with the system specs, the codes are broken and there are infinite loops.
By changing the input image/delete input image/ playing around with reload a bit, you can loop the program endlessly and then it won't fix.When you open it again, the result is the same.the program becomes useless.
Hello! First of all, I wanna thank you for your work, It's great! I reach out, because I'm facing an issue. The software worked great until yesterday, but today it is stuck in "Processing..." I opened the debug window and it says: "NullReferenceException: Object reference not set to an instance of an object" I deleted the folder and copied it againt, but no luck so far. Do you have any tip? Thank you!
Thanks for reaching out! :) Can you open the options - > open settings folder button - > send me the player file on Discord (Sunija#6598)? :)
Also, if you close aiimages, delete everything in the settings folder and run it again, the bug should disappear (but you won't see your old pictures in the tool again :( ).
If others are curious you can use any image you want in this software if you just rename another png to another png that was created by the software in the outputs folder, and restart the software - it will show you the new images to then inpaint. It also doesn't care about the previous images file size or resolution. Make sure you put clothes on any undressed women you come across since only a sinner would use it to do the opposite.
Hopefully we can get a feature to replace these files instead of having to rename them ourselves though or if someone else has another solution.
Hello, thanks again for the reply. I really want to reiterate how amazing you are at creating software. I use Unity to create VR environments and have spent 1000s of hours as its my daily tool besides Blender and wish I had even 1% of the knowledge you do to create something as impressive as this.
Well, the reason I ask is because I want to "mass import" images, and if you use the load from the PC I am always getting "black" in the section that I use to inpaint, unless I actually physically replace another image by copying another file over with the same file name. I found a trick to mass import 100s of files at once, but an official method to just drag and drop PC files to load into the history to have quick access to make quick inpaints would be really useful since I am using the tool to inpaint hundreds of images and loading individual images straight from the PC always causes the black issue (I can screenshot or share more details if others aren't having this issue). I tried with dozens of images using the load from box, and is always black when I try to use (not created from software, just images on the HD, works fine if I use the load image to use one from aiimages).
I also noticed one minor problem and is maybe my PC resolution (4k, using 200% windows scaling) and is a bug, or is no one else has had any reason to create 40+ templates, but it runs off the screen and you can't scroll down / see more of the templates past a certain point.
Even modifying the UI scale in software, and using the scroll bar or do anything it still runs off the page. I have about 60 templates and can't see past the 40 on screen. Could you please look into this? The reason it is blank is because I moved the images out of the folder to take screenshots so them being blank is not an issue.
Thanks for your time (again!) in answering questions and helping us users in the comments by the way. Its really cool to see a developer passionate about making their product better especially since is such a game changer in the technological landscape. Every person I've seen talk about aiimages says is the best GUI and easiest setup and boy does it work...I'm at 10 gig of images created, nothing takes more than like 20 seconds and can just set a prompt, leave the room and come back to see 1000s of new images. I'm going to use aiimages actually to completely texture an environment and models from blender and Unity to see what kind of amazing thing can be created with just prompts and I bet the answer is "better than if I spent hours (days if not months) in photoshop!"
Embeddings please in the next version also if it isn't too much trouble :)
Hello I don't know why but I can't reply to the earlier comment from you so thanks again for the assistance in implementing waifu diffusion. If you could please add the embedding feature so we could train it on images it doesn't have access to so we can add our own art styles/imagery it would be greatly appreciated. I think you have created the best software ever compiled into exe format, congratulations.
Also, is there something I am missing in how to get the img2img work? It doesn't seem to work with outside images. Even if you replace the PNG file with another file it doesn't show the correct output in the software, but then if you go to the outputs folder you can see it is being modified. This is great, because we can use your img2img feature with any image we want but it doesn't properly show the outputs. Maybe I am creating more work for myself but I can't seem to use outside images unless created with the software? Is this intentional? Because i would like to propose a method to simply "replace" files with other png on your hard drive, since that DOES show the proper data when generated, just requires having to rename each file individually to something in the outputs and then overwriting which takes a while to do lots of images.
Did you start it via the desktop shortcut? That one is broken atm. :X Will be fixed with the next patch. For now, just start it by double clicking the executable.
No, I start the app from the folder. It worked once. If I start it again the app loads the weight, the model, continually and it doesn't finish.
I rebooted and it worked again.
I tried to replace the model file with the mine edited one which it's trained for my pictures but the results were distorted, with overexposed colors and not good composed.
Also deleting the folder and extracting the files again gives the same error.
My laptop gpu has 4 Gb vram.
I used the same model on stable-diffusion-webui installed on my pc and it works perfectly loading an image in 35 seconds, also if the GFPGAN feature to fix face causes error Cuda out of memory, maybe because it needs some configurations.
Hello, first off thank you this is absolutely incredible. My first foray into the world of stable diffusion and I can't believe what I am seeing! Is there any way in the future we will have the ability to train it to get better results? It seems they didn't train it anything explicit to make hentai art with. Thank you.
You might want to replace your model with waifu diffusion.
1) Download the waifu diffusion model here: https://github.com/harubaru/waifu-diffusion/blob/main/docs/en/weights/danbooru-7... 2) Open folder aiimages_standalone\stable-diffusion\models\ldm\stable-diffusion-v1 3) Rename your old model file to "model_original" 4) Copy the downloaded waifu diffusion model there and call it "model" 5) Run aiimag.es
There is also something called "embeddings", where you can teach the AI new words (needs 5 images of the word and 1h on a RTX 3090ti). I might add a UI for that later or - if you are really really tech savvy - you can run it via the "stable-diffusion" folder in a command line. https://github.com/invoke-ai/InvokeAI/blob/main/docs/features/TEXTUAL_INVERSION....
Hello, I already have a working Stable Diffusion install after following a Youtube video tutorial, but it's just a command prompt and so it's not very intuitive to use. Therefore, I really want to use this GUI. However, I am having a problem where the output images are all green squares.
This also happened to me on my other Stable Diffusion install, but I found out that if I type "--precision full" after a prompt, it works as expected.
I have a Geforce 1660 Super GPU which apparently causes some problems for Stable Diffusion. But since I was able to find a solution for my other Stable Diffusion install, I wonder if I could do that here too?
In short: is it possible to have "--precision full" run every time I generate an image, so that the output image isn't a blank green square?
Edit: In the settings json, I found "bFullPrecision" which is set to true. Assuming that this is the same thing as "--precision full", but it still doesn't work, well... that is worrisome for me. Is "bFullPrecision" the same as "--precision full"? If not, my above question still stands, but if it is, then would you happen to know of any other solution for a 1660 Super GPU to output images correctly?
For reference, this is the video tutorial I followed to get a working Stable Diffusion install on my PC, that runs on the command line.
And when I type "--precision full", it works perfectly. So Stable Diffusion can indeed work on a 1660 Super, but I don't know exactly how it works.
As you already saw: Aiimag.es already applies full_precision for those graphic cards, but there's a bug in the backend that doesn't make it work (yet). :(
Apparently the 1650 models might not work at all. :(
The fix that makes the 1650 models work needs more VRAM than the 1650 model has. I'll keep you updated if the backend devs find a way to still make it work! <3
Can you open the options - > open settings folder button - > send me the player file on Discord (Sunija#6598)? v1.1.2 should work on your GPU, so maybe there's another issue. :3
Aiimages uses a history file that is saved to "C:\Users\[Your Username]\AppData\LocalLow\sunija\aiimages" to find previous images. Did that one get deleted by any chance?
Also make sure that the outputs folder is called "outputs" and is in the same folder as the executable.
If neither of those work, you can drop the images in the application or click on the empty input image, to load them as inputs. Also you can drop the images in https://www.metadata2go.com/ to get your settings, prompt, seed, etc, to recreate the images (which is tedious, though :/).
History file and outputs folders are where they are supposed to be and the files names are unchanged. Program continues to work fine. For whatever reason I cannot drag and drop images into the application like you mentioned, but I was able to recreate the images by clicking the empty input image and loading them as input image and running them with the influence cranked all the way up.
as far as i'm aware, there aren't. it'd be cool if they added it in the next update, if the user wanted to exclude certain results. thats just a suggestion tho
I've been trying to get this program to work for a few hours now but all I get it to do is generate the same 4 pictures that use the character at the top right of the page. Is there something I'm missing?
That indicates that something is crashing. You could try generating a smaller image first. If you open the options - > open settings folder button - > send me the player file via Discord (Sunija#6598), then I might give you a better answer. :3
Stable diffusion is - by default - without filter. :)
No local installations has a filter, unless somebody puts in the effort to develop one. The filters that are used for websites like dreamstudio.ai are not open source (as far as I know).
← Return to tool
Comments
Log in with itch.io to leave a comment.
I just wanted to thank you for all of your hard work. You saved us a lot of time during installation. And the user interface is nothing short of excellent; it is extremely easy to use.
Hi I have a 2060 with 6GB of RAM and the app should run fine, but everytime I try to open and access it, it shows up a warning:
Please help me thank you.
Hello, can somebody tell me why the upscale function works well BUT keeps drawing faces all around? Like in every shadow, every corner etc? Thank you
If you got the "HD" checkmark set, it will use img2img to add more details. That works well for landscapes/cities, but for people it might add unwanted faces.
In that case you'd want to remove the "HD" checkmark, so the image only gets sharper. :)
Oooh that's why! Thank you a lot
Has there been a way to get this running on a 1650 yet? im using my main laptop and thats the gpu im stuck wit
Not yet. :( And unless Nvidia can fix the problem with 16xx cards, it might never work.
for the distubing in my coment, i honestly XD.
Thank you bro
i need pay for this? -.- HHHMMMMmmmm... ok SSSSIIIII!!!! XXX Muajajaja and art obvielus.
everthing is working perfecly, but i can't generate variations of images from my pc, it just loads forever, how do i fix this?
Can you write me on Discord (Sunija#6598 or the server that is linked in the description)? :)
Then we can look at it together.
Path contain space. Try somewhere like C:\Downloads\ or D:\Downloads\ or D:\StableD. No space in path.
Why only 150 steps max? I used to do 250/300 steps with another older version and results got advantage of it
You can increase the maximum step count by...
1) Options -> open settings folder
2) Close aiimages.
3) Open settings.json with Editor. Edit the line ""iMaxStepCount": 150,". Save it.
4) Open aiiamges.
Sorry that there's not easier way yet. :( Will come in the future. <3
Thank you for your reply. Can I also ask if there is a way to choose a custom output folder different from the default one? I wanted to use the software in an M2 and output it on a external HD
Will you be updating to 1.5 Stable Diffusion that released two days ago?
Yep, next update will have it.
But you can already use the 1.5 model. Just go to options -> add custom model -> follow the steps there. :)
Eager for your update dude. Your app is by far the most enjoyable way I've found to use this tech locally on windows. Thanks for all you are doing!
Still can't get it to work with my 1660TI despite the settings saying it should work .
Thanks for reaching out! :) The 1660TI should work.
Can you join the Discord (or write me directly to Sunija#6598) and send me "open the options -> open settings folder button -> the player file"? :)
Mono path[0] = 'C:/Users/User/Downloads/aiimages-win/aiimages_Data/Managed'
Mono config path = 'C:/Users/User/Downloads/aiimages-win/MonoBleedingEdge/etc'
Initialize engine version: 2020.3.16f1 (049d6eca3c44)
[Subsystems] Discovering subsystems at path C:/Users/User/Downloads/aiimages-win/aiimages_Data/UnitySubsystems
GfxDevice: creating device client; threaded=1
Direct3D:
Version: Direct3D 11.0 [level 11.1]
Renderer: NVIDIA GeForce GTX 1660 Ti (ID=0x2191)
Vendor:
VRAM: 5991 MB
Driver: 27.21.14.6231
Begin MonoManager ReloadAssembly
- Completed reload, in 0.179 seconds
D3D11 device created for Microsoft Media Foundation video decoding.
<RI> Initializing input.
<RI> Input initialized.
<RI> Initialized touch support.
UnloadTime: 0.826100 ms
[10/22/2022 1:14:39 AM] Loading settings
[10/22/2022 1:14:39 AM] Loading history.
[10/22/2022 1:14:39 AM] Loading savegame
[10/22/2022 1:14:39 AM] <b>Your graphics card</b>: NVIDIA GeForce GTX 1660 Ti (6 GB)
Should work! <3
Writing: C:
Writing: cd "C:/Users/User/Downloads/aiimages-win/aiimages_Data/../stable-diffusion"
Writing: activate ldm
Writing: set TRANSFORMERS_CACHE=C:/Users/User/Downloads/aiimages-win/aiimages_Data/../ai_cache/huggingface/transformers
Writing: set TORCH_HOME="C:/Users/User/Downloads/aiimages-win/aiimages_Data/../ai_cache/torch"
Writing: python scripts/dream.py
[10/22/2022 1:14:40 AM] Saving settings.
>>>>>>>> Microsoft Windows [Version 10.0.19044.2130]
>>>>>>>> (c) Microsoft Corporation. All rights reserved.
>>>>>>>> C:\Users\User\Downloads\aiimages-win>call C:/Users/User/Downloads/aiimages-win/aiimages_Data/../env/Scripts/activate.bat
>>>>>>>> (env) C:\Users\User\Downloads\aiimages-win>C:
>>>>>>>> (env) C:\Users\User\Downloads\aiimages-win>cd "C:/Users/User/Downloads/aiimages-win/aiimages_Data/../stable-diffusion"
>>>>>>>> (env) C:\Users\User\Downloads\aiimages-win\stable-diffusion>activate ldm
>>>>>>>> (env) C:\Users\User\Downloads\aiimages-win\stable-diffusion>set "TRANSFORMERS_CACHE=C:/Users/User/Downloads/aiimages-win/aiimages_Data/../ai_cache/huggingface/transformers"
>>>>>>>> (env) C:\Users\User\Downloads\aiimages-win\stable-diffusion>set "TORCH_HOME=C:/Users/User/Downloads/aiimages-win/aiimages_Data/../ai_cache/torch"
>>>>>>>> (env) C:\Users\User\Downloads\aiimages-win\stable-diffusion>python scripts/dream.py -o "C:/Users/User/Downloads/aiimages-win/aiimages_Data/../outputs"
I've been using this thing non-stop like 5+ hours a day. It just is so much fun.
I've spent the past day or so reading up on the embeddings/textual inversion and google colab/Dreambooth options as well to train the stable diffusion model more, but it seems every option becomes difficult to various reasons - and the other options require you to pay to run a server farm to train the model for you.
Is there any chance you are working on or can put together a UI so we can train and create our own model.ckpt file directly in the software? I've looked at other options but require installing Ubuntu in Windows, or having to go through all that difficult Python scripts when we just want to be able to drag and drop images, click go and come back to a sweet new file.
Please, if you could just include a simple UI it would mean the world to myself and so many others. Your option to generate unlimited images makes it far better than the other stable diffusion UIs.
Awesome to hear that you like it so much! <3
I think you cannot train an own model.ckpt on consumer hardware. :( And it needs about 40k images with labels. But there are two things I might add.
A) Embeddings. You can find those in the documentation for invokeai. Basically: Give the ai "5 images + 1 tag + 1h training on a RTX 3090ti = ai learned new word". I could create a UI for that already.
B) Dreambooth. I don't understand it yet, but it's kinda "embeddings but better", if I understood it correctly. It is not implemented in the backend yet, but it will be implemented. I'm kinda hyped for that, because it allows to create the same person in different poses. <3
Pretty impressed by what it can spit down with a nice prompt and some fine tuning. It can even manage some pretty face and hands instead of the distorted monstruosity that i saw in some other browser based generator.
It seem to get stuck on an infinite loading while i try to upscale or repeat an already upscaled / repeated image, but still for a generous price tag of free is one of the best tool that i've ever seen
:O That's actually a really impressive hand.
Would be cool if you could poke me on discord (either on the server, or directly Sunija#6598) so we can try to fix the infinite loading. <3
HI i just downloaded this and it said that the module took to long if you could help me out that would be helpful
(and if you need my pc specs here they are)
ram :16
CPU: Ryzen 5000 series
gpu:1650
Sadly, it won't work with the gtx 1650. :(
The GTX 1650 has two problems that make it the only Nvidia card with sufficient RAM to not work. :(
all right , thanks
Thank you. All other functions work normally. Only in the inpaint, if you want to modify the image partially, it will be stuck all the time. Why? (3060ti)
Thanks for reaching out! :)
Would be cool if you could poke me on discord (either on the server, or directly Sunija#6598) so we can try to fix that. <3
recently ive seen some rlly cool ai animation videos that show a bunch of ai generated images together like an animated video using stable diffusion and I was just curious if its possible to do with this?
aiimag.es cannot do videos (yet?) and maybe I won't have the time to add them. :(
But if you (or somebody else) finds a cool tool to do videos, feel free to post it here. <3
i asked around and there's something called Deforum Stable Diffusion: https://github.com/HelixNGC7293/DeforumStableDiffusionLocal
i have not clue how to use it but some ppl might find it cool
would greatly appreciate some kind of integration or pipeline for Textual Inversion to use our own images to train for those of us that are far less program savvy!
1660ti may be worked by “——medvram”or“——lowvram” --precision full --no-half
Thanks for the help! :)
With the newest version, aiimages already sets the right values to run on the GPU. (It only won't work on the 1650, because it doesn't have enough VRAM for the fix. :( )
where can I get the newest version?
Newest version is above the one that only says "aiimag.es download". :)
yeah,I saw it,Version 5 14 days ago,and still doesnt work。。
First, thanks for sharing this fantastic tool. It's incredible to create cool variations of self-painted images :)
Is there a way to also extend images with new content like in DallE? :)
Not yet, might come with the next update. :)
(The backend already supports it, I'll just have to write the UI for it. :X)
how to get adult contents,i try some nsfw words but can't work.is there some safe check just inside and invisible?
Not with my experience. I rather accidently created some nsfw stuff just by adding the word "sexy" or so. Try adding more words describing what you want?
also this model takes a Finnneeee time to load
Can you make 512 by 512 images with a 4gb of vram?
Should be possible in general. Did the model finish loading for you? :3
e.g; I selected an input image, then deleted that input image from the program's folder. (using windows explorer)
then all the pictures I wanted to reprocess took hundreds of seconds, the program went into an infinite loop and the rendering was never finished. gpu usage is %1, cpu usage is %1. vram and ram is totally empty.
You need to fix the coding. There are dozens of ways to put the program in an infinite loop. CPU and gpu usage stays at 1% during this process. this has nothing to do with the system specs, the codes are broken and there are infinite loops.
By changing the input image/delete input image/ playing around with reload a bit, you can loop the program endlessly and then it won't fix. When you open it again, the result is the same. the program becomes useless.
nice effort but extremely buggy, need a hotfixes.
anyway thanks for effort.
Hello! First of all, I wanna thank you for your work, It's great!
I reach out, because I'm facing an issue. The software worked great until yesterday, but today it is stuck in "Processing..." I opened the debug window and it says: "NullReferenceException: Object reference not set to an instance of an object" I deleted the folder and copied it againt, but no luck so far. Do you have any tip? Thank you!
Thanks for reaching out! :)
Can you open the options - > open settings folder button - > send me the player file on Discord (Sunija#6598)? :)
Also, if you close aiimages, delete everything in the settings folder and run it again, the bug should disappear (but you won't see your old pictures in the tool again :( ).
If others are curious you can use any image you want in this software if you just rename another png to another png that was created by the software in the outputs folder, and restart the software - it will show you the new images to then inpaint. It also doesn't care about the previous images file size or resolution. Make sure you put clothes on any undressed women you come across since only a sinner would use it to do the opposite.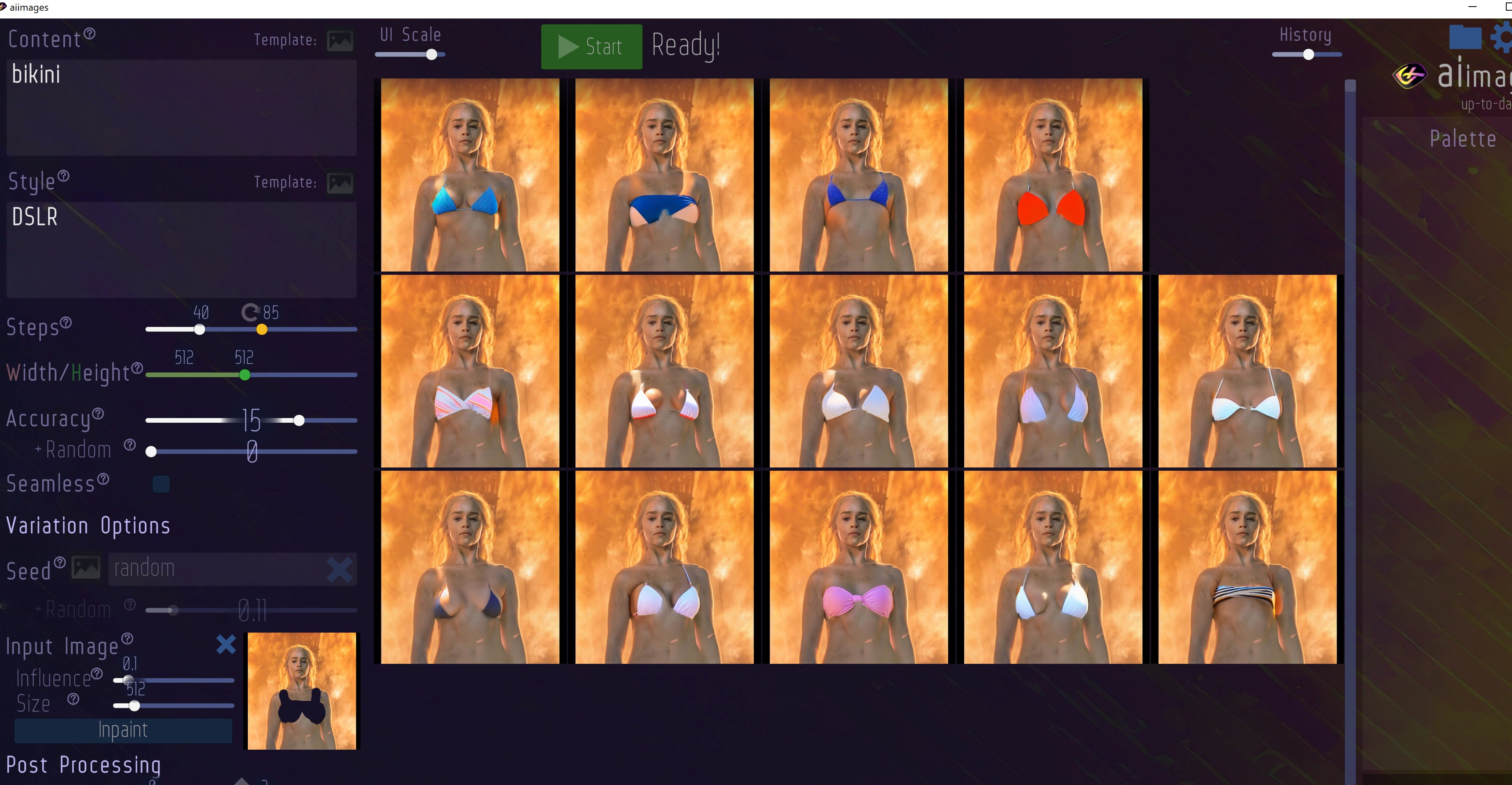
Hopefully we can get a feature to replace these files instead of having to rename them ourselves though or if someone else has another solution.
In the new version, you can just drag'n'drop an image on the tool. :)
In the old version, you can click on the input image to load one from your PC.
Hello, thanks again for the reply. I really want to reiterate how amazing you are at creating software. I use Unity to create VR environments and have spent 1000s of hours as its my daily tool besides Blender and wish I had even 1% of the knowledge you do to create something as impressive as this.
Well, the reason I ask is because I want to "mass import" images, and if you use the load from the PC I am always getting "black" in the section that I use to inpaint, unless I actually physically replace another image by copying another file over with the same file name. I found a trick to mass import 100s of files at once, but an official method to just drag and drop PC files to load into the history to have quick access to make quick inpaints would be really useful since I am using the tool to inpaint hundreds of images and loading individual images straight from the PC always causes the black issue (I can screenshot or share more details if others aren't having this issue). I tried with dozens of images using the load from box, and is always black when I try to use (not created from software, just images on the HD, works fine if I use the load image to use one from aiimages).
I also noticed one minor problem and is maybe my PC resolution (4k, using 200% windows scaling) and is a bug, or is no one else has had any reason to create 40+ templates, but it runs off the screen and you can't scroll down / see more of the templates past a certain point.
Even modifying the UI scale in software, and using the scroll bar or do anything it still runs off the page. I have about 60 templates and can't see past the 40 on screen. Could you please look into this? The reason it is blank is because I moved the images out of the folder to take screenshots so them being blank is not an issue.
Thanks for your time (again!) in answering questions and helping us users in the comments by the way. Its really cool to see a developer passionate about making their product better especially since is such a game changer in the technological landscape. Every person I've seen talk about aiimages says is the best GUI and easiest setup and boy does it work...I'm at 10 gig of images created, nothing takes more than like 20 seconds and can just set a prompt, leave the room and come back to see 1000s of new images. I'm going to use aiimages actually to completely texture an environment and models from blender and Unity to see what kind of amazing thing can be created with just prompts and I bet the answer is "better than if I spent hours (days if not months) in photoshop!"
Embeddings please in the next version also if it isn't too much trouble :)
Hello I don't know why but I can't reply to the earlier comment from you so thanks again for the assistance in implementing waifu diffusion. If you could please add the embedding feature so we could train it on images it doesn't have access to so we can add our own art styles/imagery it would be greatly appreciated. I think you have created the best software ever compiled into exe format, congratulations.
Also, is there something I am missing in how to get the img2img work? It doesn't seem to work with outside images. Even if you replace the PNG file with another file it doesn't show the correct output in the software, but then if you go to the outputs folder you can see it is being modified. This is great, because we can use your img2img feature with any image we want but it doesn't properly show the outputs. Maybe I am creating more work for myself but I can't seem to use outside images unless created with the software? Is this intentional? Because i would like to propose a method to simply "replace" files with other png on your hard drive, since that DOES show the proper data when generated, just requires having to rename each file individually to something in the outputs and then overwriting which takes a while to do lots of images.
Anyone else getting the "failed to load mono" error when running the exe?
Thanks for reaching out!
1) Are you on a Windows PC?
2) Did you install it to a very deep folder? (E.g. C:/a_very_long_foldername/and_another_one/aiimages/)
If 2 is the case, copy it to a higher folder (E.g. C:/Data/) and unzip it there again. Or use the itch.io/app to install aiimages. :)
Only works for Nvidia graphics?
Yep, atm it will sadly only work with Nvidia cards. :(
AMD might follow with later patches.
Ah okey :) Thanks for the Info
First time I open aiimages the model gets loaded, if I close the application and load it again it loads continually and doesn't finish
Did you start it via the desktop shortcut?
That one is broken atm. :X Will be fixed with the next patch. For now, just start it by double clicking the executable.
No, I start the app from the folder. It worked once. If I start it again the app loads the weight, the model, continually and it doesn't finish.
I rebooted and it worked again.
I tried to replace the model file with the mine edited one which it's trained for my pictures but the results were distorted, with overexposed colors and not good composed.
Also deleting the folder and extracting the files again gives the same error.
My laptop gpu has 4 Gb vram.
I used the same model on stable-diffusion-webui installed on my pc and it works perfectly loading an image in 35 seconds, also if the GFPGAN feature to fix face causes error Cuda out of memory, maybe because it needs some configurations.
i have RX 570 4gb found or not?
The RX 570 won't work (yet), because it is an AMD card, not a Nvidia one. :(
AMD cards might work with future updates.
i see and is very sad :'v
Greatly appreciated! Love the 90s style UI!
Keep up the awesome work!
Hello, first off thank you this is absolutely incredible. My first foray into the world of stable diffusion and I can't believe what I am seeing! Is there any way in the future we will have the ability to train it to get better results? It seems they didn't train it anything explicit to make hentai art with. Thank you.
You might want to replace your model with waifu diffusion.
1) Download the waifu diffusion model here: https://github.com/harubaru/waifu-diffusion/blob/main/docs/en/weights/danbooru-7...
2) Open folder aiimages_standalone\stable-diffusion\models\ldm\stable-diffusion-v1
3) Rename your old model file to "model_original"
4) Copy the downloaded waifu diffusion model there and call it "model"
5) Run aiimag.es
There is also something called "embeddings", where you can teach the AI new words (needs 5 images of the word and 1h on a RTX 3090ti). I might add a UI for that later or - if you are really really tech savvy - you can run it via the "stable-diffusion" folder in a command line. https://github.com/invoke-ai/InvokeAI/blob/main/docs/features/TEXTUAL_INVERSION....
does it still work with the new version of Stable Diffusion?
Any plans on making a Linux build for this?
I'd love to!
But I don't have a Linux system to test the (necessary but few) changes on, yet. :/
Well if you need testing on linux i can be of service. Dont know anything about stable diffusion but running ubuntu and unity on it.
Hello, I already have a working Stable Diffusion install after following a Youtube video tutorial, but it's just a command prompt and so it's not very intuitive to use. Therefore, I really want to use this GUI. However, I am having a problem where the output images are all green squares.
This also happened to me on my other Stable Diffusion install, but I found out that if I type "--precision full" after a prompt, it works as expected.
I have a Geforce 1660 Super GPU which apparently causes some problems for Stable Diffusion. But since I was able to find a solution for my other Stable Diffusion install, I wonder if I could do that here too?
In short: is it possible to have "--precision full" run every time I generate an image, so that the output image isn't a blank green square?
Edit: In the settings json, I found "bFullPrecision" which is set to true. Assuming that this is the same thing as "--precision full", but it still doesn't work, well... that is worrisome for me. Is "bFullPrecision" the same as "--precision full"? If not, my above question still stands, but if it is, then would you happen to know of any other solution for a 1660 Super GPU to output images correctly?
For reference, this is the video tutorial I followed to get a working Stable Diffusion install on my PC, that runs on the command line.
And when I type "--precision full", it works perfectly. So Stable Diffusion can indeed work on a 1660 Super, but I don't know exactly how it works.Thanks for reaching out!
As you already saw: Aiimag.es already applies full_precision for those graphic cards, but there's a bug in the backend that doesn't make it work (yet). :(
I hope I can fix it by today/tomorrow!
and 1650 super, too, please correct)))
Apparently the 1650 models might not work at all. :(
The fix that makes the 1650 models work needs more VRAM than the 1650 model has. I'll keep you updated if the backend devs find a way to still make it work! <3
Man, I will be so happy if you fix this. 1660TI - same problems with green cubes, but your tool is awesome!
Is fixed now. :)
Thank you! I'm excited for it to be fixed in the coming days.
Is fixed. :)
my card is 1660TI too.And i got green cube on v1.1.1,but got nothing on v1.1.2 ...
I'm excited for it to be fixed in 1.1.3
love u
Can you open the options - > open settings folder button - > send me the player file on Discord (Sunija#6598)?
v1.1.2 should work on your GPU, so maybe there's another issue. :3
dude,my card is 1660TI too!did have fixed this problem?
Should be fixed in the newest version. :)
Thank you for using aiimages! <3
Aiimages uses a history file that is saved to "C:\Users\[Your Username]\AppData\LocalLow\sunija\aiimages" to find previous images. Did that one get deleted by any chance?
Also make sure that the outputs folder is called "outputs" and is in the same folder as the executable.
If neither of those work, you can drop the images in the application or click on the empty input image, to load them as inputs. Also you can drop the images in https://www.metadata2go.com/ to get your settings, prompt, seed, etc, to recreate the images (which is tedious, though :/).
History file and outputs folders are where they are supposed to be and the files names are unchanged. Program continues to work fine. For whatever reason I cannot drag and drop images into the application like you mentioned, but I was able to recreate the images by clicking the empty input image and loading them as input image and running them with the influence cranked all the way up.
Your reply was a big help, thanks!
are there negative prompts?
as far as i'm aware, there aren't. it'd be cool if they added it in the next update, if the user wanted to exclude certain results. thats just a suggestion tho
The new update (v1.1.2) added negative prompts. :)
I've been trying to get this program to work for a few hours now but all I get it to do is generate the same 4 pictures that use the character at the top right of the page. Is there something I'm missing?
Thanks for reaching out!
That indicates that something is crashing. You could try generating a smaller image first.
If you open the options - > open settings folder button - > send me the player file via Discord (Sunija#6598), then I might give you a better answer. :3
Hi! Quick question. Does this have any sort of censorship filter on it?
No, there is no filter.
sus
Stable diffusion is - by default - without filter. :)
No local installations has a filter, unless somebody puts in the effort to develop one. The filters that are used for websites like dreamstudio.ai are not open source (as far as I know).
heeeyyy i didnt know how else to message you but im doing well
Oh! Hey! It's good to hear from you! Annoying itch doesn't have DMs, but I'm glad you're doing well. Apologies if it came across as prying!
naaah u good !
oh jesus I think I'm actually gonna make an RPG in this. The challenge: everything used has to be the first draft.