Did you start it via the desktop shortcut? That one is broken atm. :X Will be fixed with the next patch. For now, just start it by double clicking the executable.
No, I start the app from the folder. It worked once. If I start it again the app loads the weight, the model, continually and it doesn't finish.
I rebooted and it worked again.
I tried to replace the model file with the mine edited one which it's trained for my pictures but the results were distorted, with overexposed colors and not good composed.
Also deleting the folder and extracting the files again gives the same error.
My laptop gpu has 4 Gb vram.
I used the same model on stable-diffusion-webui installed on my pc and it works perfectly loading an image in 35 seconds, also if the GFPGAN feature to fix face causes error Cuda out of memory, maybe because it needs some configurations.
Hello, first off thank you this is absolutely incredible. My first foray into the world of stable diffusion and I can't believe what I am seeing! Is there any way in the future we will have the ability to train it to get better results? It seems they didn't train it anything explicit to make hentai art with. Thank you.
You might want to replace your model with waifu diffusion.
1) Download the waifu diffusion model here: https://github.com/harubaru/waifu-diffusion/blob/main/docs/en/weights/danbooru-7... 2) Open folder aiimages_standalone\stable-diffusion\models\ldm\stable-diffusion-v1 3) Rename your old model file to "model_original" 4) Copy the downloaded waifu diffusion model there and call it "model" 5) Run aiimag.es
There is also something called "embeddings", where you can teach the AI new words (needs 5 images of the word and 1h on a RTX 3090ti). I might add a UI for that later or - if you are really really tech savvy - you can run it via the "stable-diffusion" folder in a command line. https://github.com/invoke-ai/InvokeAI/blob/main/docs/features/TEXTUAL_INVERSION....
Hello, I already have a working Stable Diffusion install after following a Youtube video tutorial, but it's just a command prompt and so it's not very intuitive to use. Therefore, I really want to use this GUI. However, I am having a problem where the output images are all green squares.
This also happened to me on my other Stable Diffusion install, but I found out that if I type "--precision full" after a prompt, it works as expected.
I have a Geforce 1660 Super GPU which apparently causes some problems for Stable Diffusion. But since I was able to find a solution for my other Stable Diffusion install, I wonder if I could do that here too?
In short: is it possible to have "--precision full" run every time I generate an image, so that the output image isn't a blank green square?
Edit: In the settings json, I found "bFullPrecision" which is set to true. Assuming that this is the same thing as "--precision full", but it still doesn't work, well... that is worrisome for me. Is "bFullPrecision" the same as "--precision full"? If not, my above question still stands, but if it is, then would you happen to know of any other solution for a 1660 Super GPU to output images correctly?
For reference, this is the video tutorial I followed to get a working Stable Diffusion install on my PC, that runs on the command line.
And when I type "--precision full", it works perfectly. So Stable Diffusion can indeed work on a 1660 Super, but I don't know exactly how it works.
As you already saw: Aiimag.es already applies full_precision for those graphic cards, but there's a bug in the backend that doesn't make it work (yet). :(
Apparently the 1650 models might not work at all. :(
The fix that makes the 1650 models work needs more VRAM than the 1650 model has. I'll keep you updated if the backend devs find a way to still make it work! <3
Can you open the options - > open settings folder button - > send me the player file on Discord (Sunija#6598)? v1.1.2 should work on your GPU, so maybe there's another issue. :3
Aiimages uses a history file that is saved to "C:\Users\[Your Username]\AppData\LocalLow\sunija\aiimages" to find previous images. Did that one get deleted by any chance?
Also make sure that the outputs folder is called "outputs" and is in the same folder as the executable.
If neither of those work, you can drop the images in the application or click on the empty input image, to load them as inputs. Also you can drop the images in https://www.metadata2go.com/ to get your settings, prompt, seed, etc, to recreate the images (which is tedious, though :/).
History file and outputs folders are where they are supposed to be and the files names are unchanged. Program continues to work fine. For whatever reason I cannot drag and drop images into the application like you mentioned, but I was able to recreate the images by clicking the empty input image and loading them as input image and running them with the influence cranked all the way up.
as far as i'm aware, there aren't. it'd be cool if they added it in the next update, if the user wanted to exclude certain results. thats just a suggestion tho
I've been trying to get this program to work for a few hours now but all I get it to do is generate the same 4 pictures that use the character at the top right of the page. Is there something I'm missing?
That indicates that something is crashing. You could try generating a smaller image first. If you open the options - > open settings folder button - > send me the player file via Discord (Sunija#6598), then I might give you a better answer. :3
Stable diffusion is - by default - without filter. :)
No local installations has a filter, unless somebody puts in the effort to develop one. The filters that are used for websites like dreamstudio.ai are not open source (as far as I know).
a slight bug report, ive notice that everytime i delete an image, the previous image duplicates. So when i delete a bunch of images, i end up with dozens of the same image. and when i try deleting any of the duplicated image, it deletes all of duplicate images including the original.
hey, whenever i try generating anything, the faces are always distorted and horribly messed up. i tried turning up the better face scale and tried clicking on the face icon but the results were always really bad. any idea how i could fix this?
also, you mentioned inpainting as an option and feature but im not quite access this feature.
1) Inpainting Drag the image into the "Input Image", then click the little blue wrench in the top right of the image preview there. Paint over the face, click "apply" and let it run again.
2) More steps Sometimes faces get better with more steps.
3) Face bigger in the picture If the face is really small in the picture, the AI seems to put less effort into it. If you can make a picture where the face takes up more space in the picture, it should work better.
4) Different prompt Some prompts just generate wonky faces. :3 Next to "style" you can press on the template image. There you can select some style templates that usually create non-distorted faces.
You can also post a picture of your setup on Discord, then we can check together if some setting maybe inhibits beautiful faces. :)
thanks for the reply, I have another minor questions though, what's the difference between the grey slider and the white slider for each of the options?
also, theres an image i generated but its sort of cut halfway. How would i change the width of the image and generate the other half of the image as well? i tried dragging the image the input but i cant seem to increase the width resolution and it just stays the same and cut in half. any recommendations? (sorry for asking so many questions, im just fascinated by the ai)
Grey slider: The value that is used for every image, when you click "start". You can think of it as a preview. White slider: The value that is used when you click on the buttons on an image. E.g. you set "Steps slider - grey: 20, white:50". Then the AI will quickly generate loooads of images, but only with 20 steps, so they might have some glitches. When you found a nice image, you click the circular arrow in the hover menu. Then the image is re-done, but this time with 50 steps, to make any glitches disappear.
Not sure if that's what happened for you: If the AI generates "two images in one", there's not much you can do atm, sorry. :/ If outpainting is added in the future, there might be a solution for that.
Thanks for making this - to make it clear - I'm not trying to bash your work - would simply want to use better version of this tool, and this GUI looks promising.
UI tooltips have very vague descriptions IMHO.
- "Steps" - Really unclear TBH. It says grey bar is for previewing. But there is no preview button. Are grey and white bars somehow related? Asking because they share the same space. If both the grey handle and white handle overlap, what happens? Or are they simply unrelated and probably better as separate sliders?
- "Accuracy" - it says default is 7.5 (which it wasn't). It also talks about yellow bar, which isn't visible by default. How does this actually work is unclear. What happens when yellow bar knob is moved right? Or when yellow bar knob is on the left edge?
- Width/height; Really strange UI, why not simply have two sliders, one for width, one for height?
Popup image preview - I find it really annoying that hovering over small thumbnail brings up a preview image size of half the application window. I'd personally expect 2x or 3x size preview. Why not make larger image preview appear if user clicks or double clicks a thumbnail?
Order of render images - I guess this depends, but I'd personally expect left to right, and then top to bottom. Now rendering order seems a bit off.
Palette - what is the purpose of this window? There is no tooltip.
Rendered images - there is no way to delete files? Dragging to trash only removes it from list. No matter what, I usually delete most of the variants, there doesn't seem to be a way to update list of images, if I manually delete the files. Also, it would be better if prompt was a separate file for each image, that way both can be stored or deleted easily. Now all the output datas are stored in one file, making it really hard to store unique results (like drag and drop the prompt and image in some other folder).
Play - could it possible to make it only render one image? Make a separate button to infinitely generate images?
- Steps tooltip: Updated the description, but it's most likely still a bit unclear. :X I hope I can release a quick tutorial video tomorrow.
- Accuracy tooltip: Also reworked, but might also need the tutorial.
- Width/height: I wanted to save space. :D But it's really not very beautiful. I'll try to find a nice solution till next version.
- Giant popup image preview: Fixed. The default preview is now smaller and at a fixed position. If you click the middle of an image, you can toggle to the big preview.
- Render order: It's top->bottom to work a bit like blogs. :3 If it wasn't left->right it might have been buggy (which wouldn't surprise me, but should be fixed now). Maybe I'll add an option to make it bottom->top.
- Palette misses tooltip: Fixed.
- Deletion: Is a lot easier now. It still only puts them in a trash folder instead of deleting them right away (until I can be sure that nobody deletes something accidentally), but you can just delete this folder from time to time then. Prompts are saved in the image's meta info atm, but you'd have to read those via an online tool... so not very handy. I'll think about a solution until next version. :)
- Tooltip boxes text bad aligned: Fixed.
- Rendered images don't show up until dragging: Fixed.
- UI dies when resizing: Fixed.
- Unclear UI: Semi-fixed. You can disable the background texture in the settings. I'll work on the rest for the next version.
Again: Thank you a lot for the feedback! <3 Helped a lot for the new release.
Some comments; - Delete mode moves renders to trashcan folder, but dropping renders into trashcan doesn't. Is this intentional?
- Main rendered images area already works better, but deleting items / resizing windows (not sure what I did) makes the list look like a jagged array. Some rows are full, others have some items. Is this intentional? Could it simply be a one continuous list, like with Grid Layout Group? I've done several UIs for my own little projects and it works great for lists like this.
- "Prompts are saved in the image's meta" - Great! BTW - simply drop your png to any text editor (like notepad++), and you'll see your stored prompt near the beginning of the file, even though most of the other stuff will be "garbage". Another way is to use some popular image viewer/file browser like XnView MP, it can show you the metadata, from Preview Image panel's Info tab, ExifTool (non-MP version doesn't have this feature AFAIK).
BTW UI has some issues. Seems like it is made with Unity and UI has several typical Unity UI issues.
- Tooltip boxes have texts badly aligned, text goes outside of bounds in left and down directions. - Rendered images don't show up, I had to drag corner of the window to make it smaller, only then rendered images appeared. I noticed that created files appeared in rendering folder and started to wonder what is going on because I didn't see anything in the UI. - The UI window can be sized dynamically, but UI elements haven't been anchored properly, some elements don't scale properly, some start to overlap each other, when window is scaled. - The main list of rendered images has issues with image grid going out of view if window is resized. I don't know if you used uGUI or the new UI Toolkit, but at least with uGUI it is fixable. - UI could use more readable and accessible look, now it is very dark and there are no clear borders between areas. At least make it so that contrast between UI and background can be seen properly. I don't see any use for textured boxes TBH, a simple, clean and easy to navigate UI would suffice.
This looks really interesting, I tried to use another SD GUI (NMKD) but kept running into problems with Python or something. I'm downloading this now (it's taking a very long time - more links/hosting on itch.io would be nice); I'll update here after I successfully test it with my 4GB VRAM Video Card and 12GB System RAM.
This GUI has the potential to be an excellent and simple way to take advantage of some of Stable Diffusion's best features.
Horrible download speeds; after several hours of downloading, the zip file was apparently corrupted. I'm giving it one more shot and downloading again. (Is it too large to host on itch.io?)
Thank you so much for your reply and assistance, Sunija.
I finally got it downloaded properly and it runs very well overall; I appreciate how easy it is to start playing with as soon as it is installed. The tooltips and other features are a great touch.
I'll definitely follow your project and recommend when I'm able.
I'm looking forward to some improvements to the interface and the planned inpainting feature.
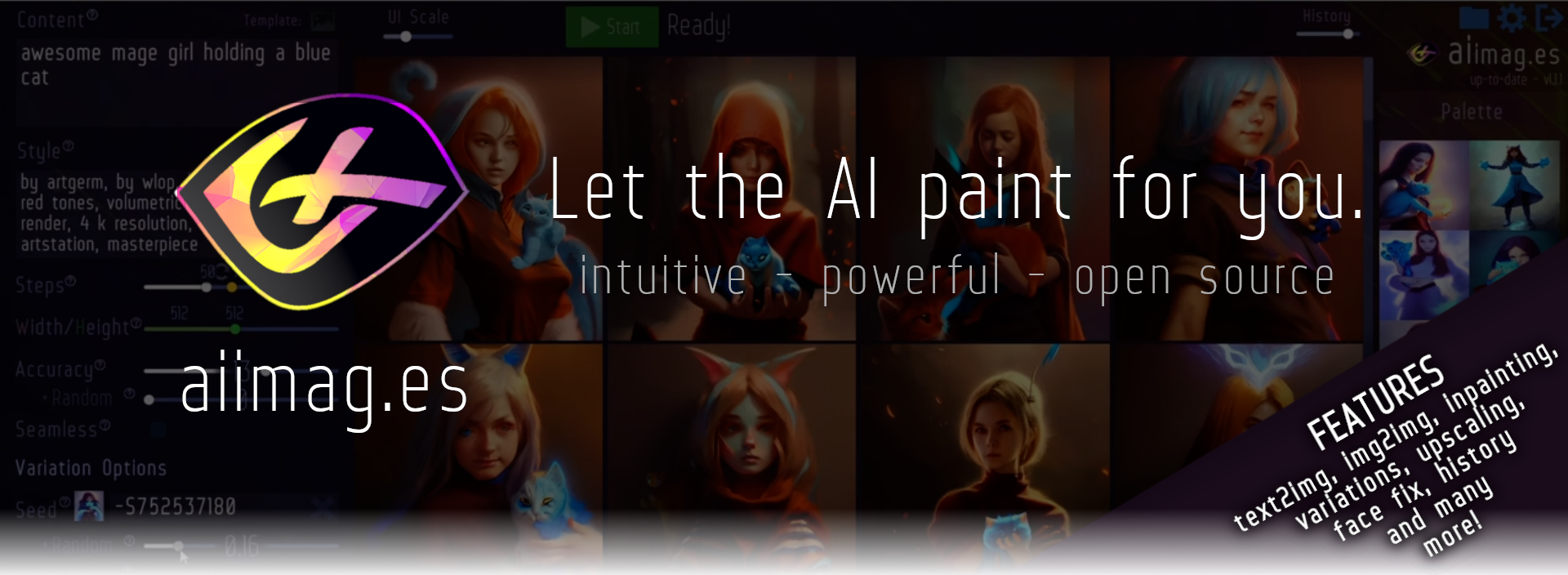
← Return to tool
Comments
Log in with itch.io to leave a comment.
First time I open aiimages the model gets loaded, if I close the application and load it again it loads continually and doesn't finish
Did you start it via the desktop shortcut?
That one is broken atm. :X Will be fixed with the next patch. For now, just start it by double clicking the executable.
No, I start the app from the folder. It worked once. If I start it again the app loads the weight, the model, continually and it doesn't finish.
I rebooted and it worked again.
I tried to replace the model file with the mine edited one which it's trained for my pictures but the results were distorted, with overexposed colors and not good composed.
Also deleting the folder and extracting the files again gives the same error.
My laptop gpu has 4 Gb vram.
I used the same model on stable-diffusion-webui installed on my pc and it works perfectly loading an image in 35 seconds, also if the GFPGAN feature to fix face causes error Cuda out of memory, maybe because it needs some configurations.
i have RX 570 4gb found or not?
The RX 570 won't work (yet), because it is an AMD card, not a Nvidia one. :(
AMD cards might work with future updates.
i see and is very sad :'v
Greatly appreciated! Love the 90s style UI!
Keep up the awesome work!
Hello, first off thank you this is absolutely incredible. My first foray into the world of stable diffusion and I can't believe what I am seeing! Is there any way in the future we will have the ability to train it to get better results? It seems they didn't train it anything explicit to make hentai art with. Thank you.
You might want to replace your model with waifu diffusion.
1) Download the waifu diffusion model here: https://github.com/harubaru/waifu-diffusion/blob/main/docs/en/weights/danbooru-7...
2) Open folder aiimages_standalone\stable-diffusion\models\ldm\stable-diffusion-v1
3) Rename your old model file to "model_original"
4) Copy the downloaded waifu diffusion model there and call it "model"
5) Run aiimag.es
There is also something called "embeddings", where you can teach the AI new words (needs 5 images of the word and 1h on a RTX 3090ti). I might add a UI for that later or - if you are really really tech savvy - you can run it via the "stable-diffusion" folder in a command line. https://github.com/invoke-ai/InvokeAI/blob/main/docs/features/TEXTUAL_INVERSION....
does it still work with the new version of Stable Diffusion?
Any plans on making a Linux build for this?
I'd love to!
But I don't have a Linux system to test the (necessary but few) changes on, yet. :/
Well if you need testing on linux i can be of service. Dont know anything about stable diffusion but running ubuntu and unity on it.
Hello, I already have a working Stable Diffusion install after following a Youtube video tutorial, but it's just a command prompt and so it's not very intuitive to use. Therefore, I really want to use this GUI. However, I am having a problem where the output images are all green squares.
This also happened to me on my other Stable Diffusion install, but I found out that if I type "--precision full" after a prompt, it works as expected.
I have a Geforce 1660 Super GPU which apparently causes some problems for Stable Diffusion. But since I was able to find a solution for my other Stable Diffusion install, I wonder if I could do that here too?
In short: is it possible to have "--precision full" run every time I generate an image, so that the output image isn't a blank green square?
Edit: In the settings json, I found "bFullPrecision" which is set to true. Assuming that this is the same thing as "--precision full", but it still doesn't work, well... that is worrisome for me. Is "bFullPrecision" the same as "--precision full"? If not, my above question still stands, but if it is, then would you happen to know of any other solution for a 1660 Super GPU to output images correctly?
For reference, this is the video tutorial I followed to get a working Stable Diffusion install on my PC, that runs on the command line.
And when I type "--precision full", it works perfectly. So Stable Diffusion can indeed work on a 1660 Super, but I don't know exactly how it works.Thanks for reaching out!
As you already saw: Aiimag.es already applies full_precision for those graphic cards, but there's a bug in the backend that doesn't make it work (yet). :(
I hope I can fix it by today/tomorrow!
and 1650 super, too, please correct)))
Apparently the 1650 models might not work at all. :(
The fix that makes the 1650 models work needs more VRAM than the 1650 model has. I'll keep you updated if the backend devs find a way to still make it work! <3
Man, I will be so happy if you fix this. 1660TI - same problems with green cubes, but your tool is awesome!
Is fixed now. :)
Thank you! I'm excited for it to be fixed in the coming days.
Is fixed. :)
my card is 1660TI too.And i got green cube on v1.1.1,but got nothing on v1.1.2 ...
I'm excited for it to be fixed in 1.1.3
love u
Can you open the options - > open settings folder button - > send me the player file on Discord (Sunija#6598)?
v1.1.2 should work on your GPU, so maybe there's another issue. :3
dude,my card is 1660TI too!did have fixed this problem?
Should be fixed in the newest version. :)
Thank you for using aiimages! <3
Aiimages uses a history file that is saved to "C:\Users\[Your Username]\AppData\LocalLow\sunija\aiimages" to find previous images. Did that one get deleted by any chance?
Also make sure that the outputs folder is called "outputs" and is in the same folder as the executable.
If neither of those work, you can drop the images in the application or click on the empty input image, to load them as inputs. Also you can drop the images in https://www.metadata2go.com/ to get your settings, prompt, seed, etc, to recreate the images (which is tedious, though :/).
History file and outputs folders are where they are supposed to be and the files names are unchanged. Program continues to work fine. For whatever reason I cannot drag and drop images into the application like you mentioned, but I was able to recreate the images by clicking the empty input image and loading them as input image and running them with the influence cranked all the way up.
Your reply was a big help, thanks!
are there negative prompts?
as far as i'm aware, there aren't. it'd be cool if they added it in the next update, if the user wanted to exclude certain results. thats just a suggestion tho
The new update (v1.1.2) added negative prompts. :)
I've been trying to get this program to work for a few hours now but all I get it to do is generate the same 4 pictures that use the character at the top right of the page. Is there something I'm missing?
Thanks for reaching out!
That indicates that something is crashing. You could try generating a smaller image first.
If you open the options - > open settings folder button - > send me the player file via Discord (Sunija#6598), then I might give you a better answer. :3
Hi! Quick question. Does this have any sort of censorship filter on it?
No, there is no filter.
sus
Stable diffusion is - by default - without filter. :)
No local installations has a filter, unless somebody puts in the effort to develop one. The filters that are used for websites like dreamstudio.ai are not open source (as far as I know).
heeeyyy i didnt know how else to message you but im doing well
Oh! Hey! It's good to hear from you! Annoying itch doesn't have DMs, but I'm glad you're doing well. Apologies if it came across as prying!
naaah u good !
oh jesus I think I'm actually gonna make an RPG in this. The challenge: everything used has to be the first draft.
a slight bug report, ive notice that everytime i delete an image, the previous image duplicates. So when i delete a bunch of images, i end up with dozens of the same image. and when i try deleting any of the duplicated image, it deletes all of duplicate images including the original.
Thanks for the report! :)
I'll try to fix that with the next version.
really amazing gui! question though, if i update to the new version, will i retain my saved prompts and styles? thanks!
If you download it manually, copy the "input" and "output" folder to your new installation. :)
If you update via itch, everything should be fine... But making a securty backup of you input/output folders won't hurt. :X
hey, whenever i try generating anything, the faces are always distorted and horribly messed up. i tried turning up the better face scale and tried clicking on the face icon but the results were always really bad. any idea how i could fix this?
also, you mentioned inpainting as an option and feature but im not quite access this feature.
Hi, thanks for reaching out! :)
There are multiple ways to improve faces:
1) Inpainting
Drag the image into the "Input Image", then click the little blue wrench in the top right of the image preview there. Paint over the face, click "apply" and let it run again.
2) More steps
Sometimes faces get better with more steps.
3) Face bigger in the picture
If the face is really small in the picture, the AI seems to put less effort into it. If you can make a picture where the face takes up more space in the picture, it should work better.
4) Different prompt
Some prompts just generate wonky faces. :3 Next to "style" you can press on the template image. There you can select some style templates that usually create non-distorted faces.
You can also post a picture of your setup on Discord, then we can check together if some setting maybe inhibits beautiful faces. :)
thanks for the reply, I have another minor questions though, what's the difference between the grey slider and the white slider for each of the options?
also, theres an image i generated but its sort of cut halfway. How would i change the width of the image and generate the other half of the image as well? i tried dragging the image the input but i cant seem to increase the width resolution and it just stays the same and cut in half. any recommendations? (sorry for asking so many questions, im just fascinated by the ai)
No shame in asking questions. <3
Grey slider: The value that is used for every image, when you click "start". You can think of it as a preview.
White slider: The value that is used when you click on the buttons on an image.
E.g. you set "Steps slider - grey: 20, white:50". Then the AI will quickly generate loooads of images, but only with 20 steps, so they might have some glitches. When you found a nice image, you click the circular arrow in the hover menu. Then the image is re-done, but this time with 50 steps, to make any glitches disappear.
Not sure if that's what happened for you:
If the AI generates "two images in one", there's not much you can do atm, sorry. :/ If outpainting is added in the future, there might be a solution for that.
The new update looks awesome; any chance you could add a update path that doesn't require downloading the entire set of files again?
If you use the itch.io downloader, it should already work like that, right? (Did it work? :X)
Otherwise: Uploading patches would be great, I'll just have to look into it. :) Might take a while.
Thanks for the suggestion!
I've never used the itch.io downloader; I'll look into that. Thanks for the reply.
Lovely, but is there any chance for a version working on AMD Gpu's?
I hope so! :)
There is a discussion to make it run on AMD for the backend that I'm using, but not much progress yet. :/
https://github.com/lstein/stable-diffusion/discussions/407
Thanks for making this - to make it clear - I'm not trying to bash your work - would simply want to use better version of this tool, and this GUI looks promising.
UI tooltips have very vague descriptions IMHO.
- "Steps" - Really unclear TBH. It says grey bar is for previewing. But there is no preview button. Are grey and white bars somehow related? Asking because they share the same space. If both the grey handle and white handle overlap, what happens? Or are they simply unrelated and probably better as separate sliders?
- "Accuracy" - it says default is 7.5 (which it wasn't). It also talks about yellow bar, which isn't visible by default. How does this actually work is unclear. What happens when yellow bar knob is moved right? Or when yellow bar knob is on the left edge?
- Width/height; Really strange UI, why not simply have two sliders, one for width, one for height?
Popup image preview - I find it really annoying that hovering over small thumbnail brings up a preview image size of half the application window. I'd personally expect 2x or 3x size preview. Why not make larger image preview appear if user clicks or double clicks a thumbnail?
Order of render images - I guess this depends, but I'd personally expect left to right, and then top to bottom. Now rendering order seems a bit off.
Palette - what is the purpose of this window? There is no tooltip.
Rendered images - there is no way to delete files? Dragging to trash only removes it from list. No matter what, I usually delete most of the variants, there doesn't seem to be a way to update list of images, if I manually delete the files. Also, it would be better if prompt was a separate file for each image, that way both can be stored or deleted easily. Now all the output datas are stored in one file, making it really hard to store unique results (like drag and drop the prompt and image in some other folder).
Play - could it possible to make it only render one image? Make a separate button to infinitely generate images?
Thanks for the detailed feedback! <3
I just updated the version, so now...
- Steps tooltip: Updated the description, but it's most likely still a bit unclear. :X I hope I can release a quick tutorial video tomorrow.
- Accuracy tooltip: Also reworked, but might also need the tutorial.
- Width/height: I wanted to save space. :D But it's really not very beautiful. I'll try to find a nice solution till next version.
- Giant popup image preview: Fixed. The default preview is now smaller and at a fixed position. If you click the middle of an image, you can toggle to the big preview.
- Render order: It's top->bottom to work a bit like blogs. :3 If it wasn't left->right it might have been buggy (which wouldn't surprise me, but should be fixed now). Maybe I'll add an option to make it bottom->top.
- Palette misses tooltip: Fixed.
- Deletion: Is a lot easier now. It still only puts them in a trash folder instead of deleting them right away (until I can be sure that nobody deletes something accidentally), but you can just delete this folder from time to time then. Prompts are saved in the image's meta info atm, but you'd have to read those via an online tool... so not very handy. I'll think about a solution until next version. :)
- Tooltip boxes text bad aligned: Fixed.
- Rendered images don't show up until dragging: Fixed.
- UI dies when resizing: Fixed.
- Unclear UI: Semi-fixed. You can disable the background texture in the settings. I'll work on the rest for the next version.
Again: Thank you a lot for the feedback! <3 Helped a lot for the new release.
Good job! Already tried the new version quickly.
Some comments;
- Delete mode moves renders to trashcan folder, but dropping renders into trashcan doesn't. Is this intentional?
- Main rendered images area already works better, but deleting items / resizing windows (not sure what I did) makes the list look like a jagged array. Some rows are full, others have some items. Is this intentional? Could it simply be a one continuous list, like with Grid Layout Group? I've done several UIs for my own little projects and it works great for lists like this.
- "Prompts are saved in the image's meta" - Great! BTW - simply drop your png to any text editor (like notepad++), and you'll see your stored prompt near the beginning of the file, even though most of the other stuff will be "garbage". Another way is to use some popular image viewer/file browser like XnView MP, it can show you the metadata, from Preview Image panel's Info tab, ExifTool (non-MP version doesn't have this feature AFAIK).
Thanks, looks interesting!
BTW UI has some issues. Seems like it is made with Unity and UI has several typical Unity UI issues.
- Tooltip boxes have texts badly aligned, text goes outside of bounds in left and down directions.
- Rendered images don't show up, I had to drag corner of the window to make it smaller, only then rendered images appeared. I noticed that created files appeared in rendering folder and started to wonder what is going on because I didn't see anything in the UI.
- The UI window can be sized dynamically, but UI elements haven't been anchored properly, some elements don't scale properly, some start to overlap each other, when window is scaled.
- The main list of rendered images has issues with image grid going out of view if window is resized. I don't know if you used uGUI or the new UI Toolkit, but at least with uGUI it is fixable.
- UI could use more readable and accessible look, now it is very dark and there are no clear borders between areas. At least make it so that contrast between UI and background can be seen properly. I don't see any use for textured boxes TBH, a simple, clean and easy to navigate UI would suffice.
This looks really interesting, I tried to use another SD GUI (NMKD) but kept running into problems with Python or something. I'm downloading this now (it's taking a very long time - more links/hosting on itch.io would be nice); I'll update here after I successfully test it with my 4GB VRAM Video Card and 12GB System RAM.
This GUI has the potential to be an excellent and simple way to take advantage of some of Stable Diffusion's best features.
Horrible download speeds; after several hours of downloading, the zip file was apparently corrupted. I'm giving it one more shot and downloading again. (Is it too large to host on itch.io?)
Thanks for reaching out!
Yeah, itch has a limit of 4 GB. :/ I'll have to check if I can throw out enough to bring it below that limit.Edit: I lied. Itch allows larger uploads if I use their butler tool. Uploading it right now. <3
For me, the download runs at 60 MB/s, but maybe they are lower if you are outside of Europe.
Thank you so much for your reply and assistance, Sunija.
I finally got it downloaded properly and it runs very well overall; I appreciate how easy it is to start playing with as soon as it is installed. The tooltips and other features are a great touch.
I'll definitely follow your project and recommend when I'm able.
I'm looking forward to some improvements to the interface and the planned inpainting feature.
Best of luck on your project!